How Podcast RSS Feeds Really Work (and Why They Power Everything at Parla)

When most people think of podcasts, they think of Spotify, Apple Podcasts, or maybe YouTube. But what they don’t realize is that none of these platforms actually host podcasts.
There’s no special deal between Apple and your favorite podcaster. And Spotify? Unless the show is a Spotify exclusive, they're just reading from the same public source as everyone else: the podcast RSS feed.
At Parla, we’ve built our platform on top of this open infrastructure—scraping and indexing over 1 million shows and 150 million episodes from these feeds to make podcast research fast, accurate, and AI-powered.
Think of it this way: if Apple Podcasts is like Netflix, Parla is like Google—but for podcasts.
Here’s how it all works behind the scenes.
What Is a Podcast RSS Feed?
At its core, a podcast is just an RSS feed—a simple XML file that tells podcast apps (like Apple, Spotify, Overcast, etc.) where to find the audio files and how to display things like episode titles, descriptions, artwork, and more.
When you "submit your podcast to Apple Podcasts," you're really just telling Apple where to find that RSS feed. Once submitted, Apple checks the feed periodically for updates. It doesn’t host or control anything. Same goes for Spotify (again, unless you're using their exclusive hosting).
Every episode you see in your podcast app was published through an update to that feed.
Why RSS Hosting Providers Exist
Since RSS feeds are the backbone of podcasting, someone has to host and maintain them. That’s where podcast hosting providers come in.
Companies like Libsyn, Buzzsprout, Transistor, and Podbean do a few key things:
-
Store your audio files
-
Generate and serve your RSS feed
-
Track downloads and listener analytics
-
Distribute your feed to directories like Apple, Spotify, Google, etc.
They're basically the web servers behind every podcast you've ever heard.
But critically, they don’t "push" episodes to Spotify or Apple. The directories pull from the feed on a regular schedule.
This decentralized, open infrastructure is what makes podcasting unique—and also what makes large-scale podcast search tricky.
How Parla Indexes the Entire Podcast Universe
At Parla, we built our system to take full advantage of this open model.
We continuously scan and scrape millions of RSS feeds, ingesting metadata from every episode—title, description, publication date, show-level tags, categories, etc.
But we don’t stop there.
We also:
-
Resolve audio files to capture accurate links and durations
-
Extract transcripts where possible to enrich episode content
-
Standardize metadata across a fragmented ecosystem of hosts
-
Deduplicate shows (since many feeds appear in multiple directories)
Once we’ve ingested the data, we feed it into our AI search engine, letting users instantly query across 150M+ episodes.
Looking for every time a CEO talked about climate policy?
Trying to find episodes featuring a specific guest?
Researching a niche topic across a decade of audio?
Parla makes it searchable—instantly.
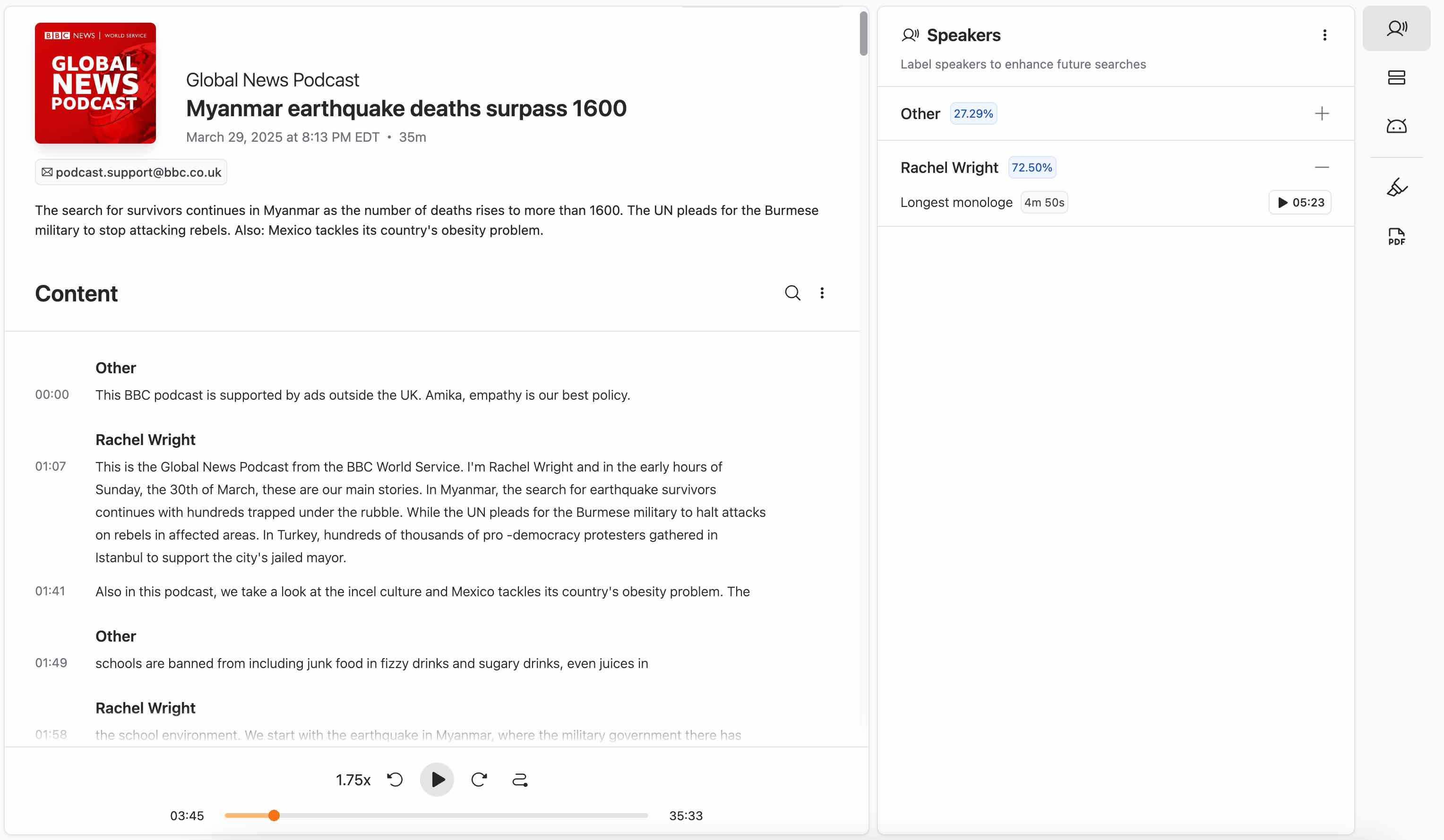
Transcripts of Any Podcast, Ever
One of the most powerful features of Parla is our transcript engine.
Even if a podcast never published a transcript, Parla can generate one on-demand. Whether it's a brand-new show or a deep cut from 2009, you can get a full transcript of any podcast episode—ever recorded.
This is a game-changer for researchers, journalists, PR teams, and marketers who need to read podcasts, quote them, analyze them, or train AI tools on them.
No more listening at 1.5x speed and taking notes. Just search, read, and act.
Want to explore the podcast universe like never before?
👉 Check out Parla.fm and see what you’ve been missing.